{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.manongdao.com/data/attach/logo/logo.png', '推荐 放我归山 的问题《Does the Inception Model have two softmax outputs?》','https://www.manongdao.com/q-329147.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
The Inception v3 model is shown in this image:
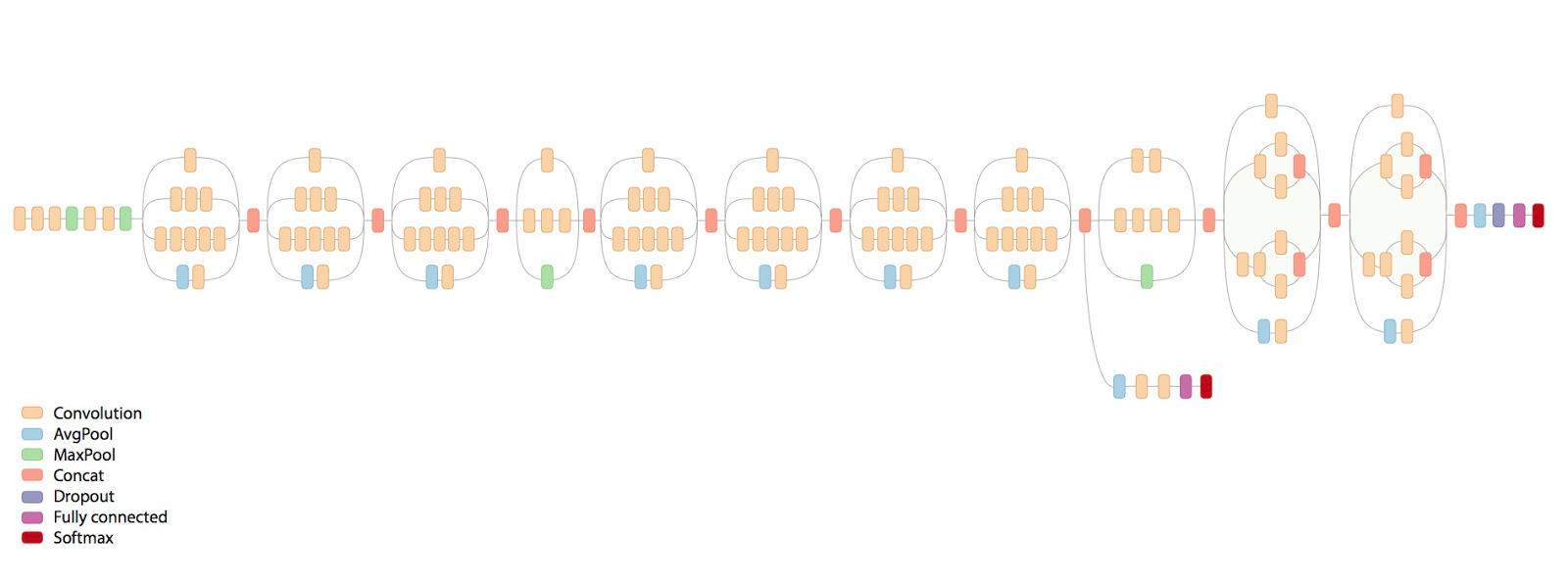
The image is from this blog-post:
https://research.googleblog.com/2016/03/train-your-own-image-classifier-with.html
It seems that there are two Softmax classification outputs. Why is that?
Which one is used in the TensorFlow example as the output tensor with the name 'softmax:0' in this file?
The academic paper for the Inception v3 model doesn't seem to have this image of the Inception model:
http://arxiv.org/pdf/1512.00567v3.pdf
I'm trying to understand why there are these two branches of the network with seemingly two different softmax-outputs.
Thanks for any clarification!
Section 4 of the paper you cite is about auxiliary classifiers. These are classifiers added to the lower levels of the network, that improve training by mitigating the vanishing gradients problem and speedup convergence. For running inference on a trained network, you should use the main classifier, called
softmax:0in the model, and NOT the auxiliary classifier, calledauxiliary_softmax:0.