{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.manongdao.com/data/attach/logo/logo.png', '推荐 一夜七次 的问题《bash, Linux: Set difference between two text files》','https://www.manongdao.com/q-260712.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
I have two files A-nodes_to_delete and B-nodes_to_keep. Each file has a many lines with numeric ids.
I want to have the list of numeric ids that are in nodes_to_delete but NOT in nodes_to_keep, e.g. alt text http://mathworld.wolfram.com/images/equations/SetDifference/Inline1.gif.
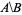{kind=link}
Doing it within a PostgreSQL database is unreasonably slow. Any neat way to do it in bash using Linux CLI tools?
UPDATE: This would seem to be a Pythonic job, but the files are really, really large. I have solved some similar problems using uniq, sort and some set theory techniques. This was about two or three orders of magnitude faster than the database equivalents.
use
comm- it will compare two sorted files line by lineexample setup
We'll use keepNodes and deleteNodes. They're are used as unsorted input.
By default without arguments, comm prints 3 columns
This is a barebones example of
commwithout arguments. Note the three columns.Suppressing column output
Suppress column 1, 2 or 3 with -N; note that when a column is hidden, the whitespace shrinks up.
It will fail gracefully when you forget to sort
comm: file 1 is not in sorted orderThe comm command does that.
Somebody showed me how to do exactly this in sh a couple months ago, and then I couldn't find it for a while... and while looking I stumbled onto your question. Here it is :
commwas specifically designed for this kind of use case, but it requires sorted input.awkis arguably a better tool for this as it's fairly straight forward to find set difference, doesn't requiresort, and offers additional flexibility.Perhaps, for example, you'd like to only find the difference in lines that represent non-negative numbers:
Maybe you need a better way to do it in postgres, I can pretty much bet that you won't find a faster way to do it using flat files. You should be able to do a simple inner join and assuming that both id cols are indexed that should be very fast.