{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.manongdao.com/data/attach/logo/logo.png', '推荐 闹够了就滚 的问题《es 单字段多分词器时,textField.keyword无法高亮》','https://www.manongdao.com/q-1472690.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
起因:
针对A字段,既需要做分词处理,有需要做聚合统计处理,因此为这个字段配置了多个类型,index和mapping如下
index
"analysis": {
"analyzer": {
"comma_analyzer": {
"tokenizer": "comma"
},
"pinyin_analyzer": {
"tokenizer": "my_pinyin"
}
},
"tokenizer": {
"comma": {
"pattern": ",",
"type": "pattern"
},
"my_pinyin": {
"keep_none_chinese_in_first_letter": "true",
"lowercase": "true",
"first_letter": "prefix",
"keep_original": "true",
"remove_duplicated_term": "true",
"keep_first_letter": "true",
"keep_separate_first_letter": "true",
"trim_whitespace": "true",
"type": "pinyin",
"keep_none_chinese": "true",
"limit_first_letter_length": "16",
"keep_full_pinyin": "true"
}
}
}
mapping
"mappings": {
"service": {
"properties": {
"关于中心": {
"analyzer": "ik_max_word",
"type": "text",
"fields": {
"comma": {
"fielddata": true,
"analyzer": "comma_analyzer",
"type": "text"
},
"suggest": {
"max_input_length": 50,
"analyzer": "pinyin_analyzer",
"preserve_position_increments": true,
"type": "completion",
"preserve_separators": true
},
"keyword": {
"type": "keyword"
}
}
}
}
}
},
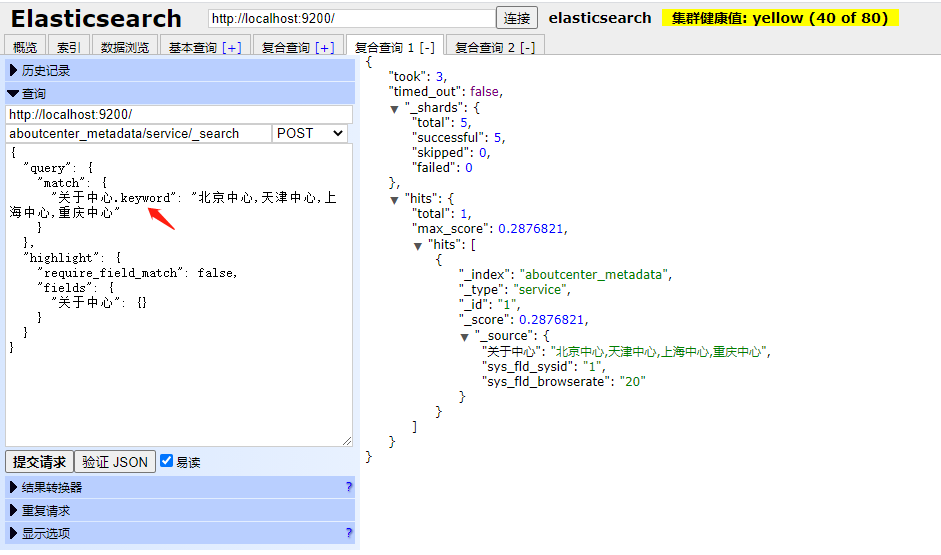
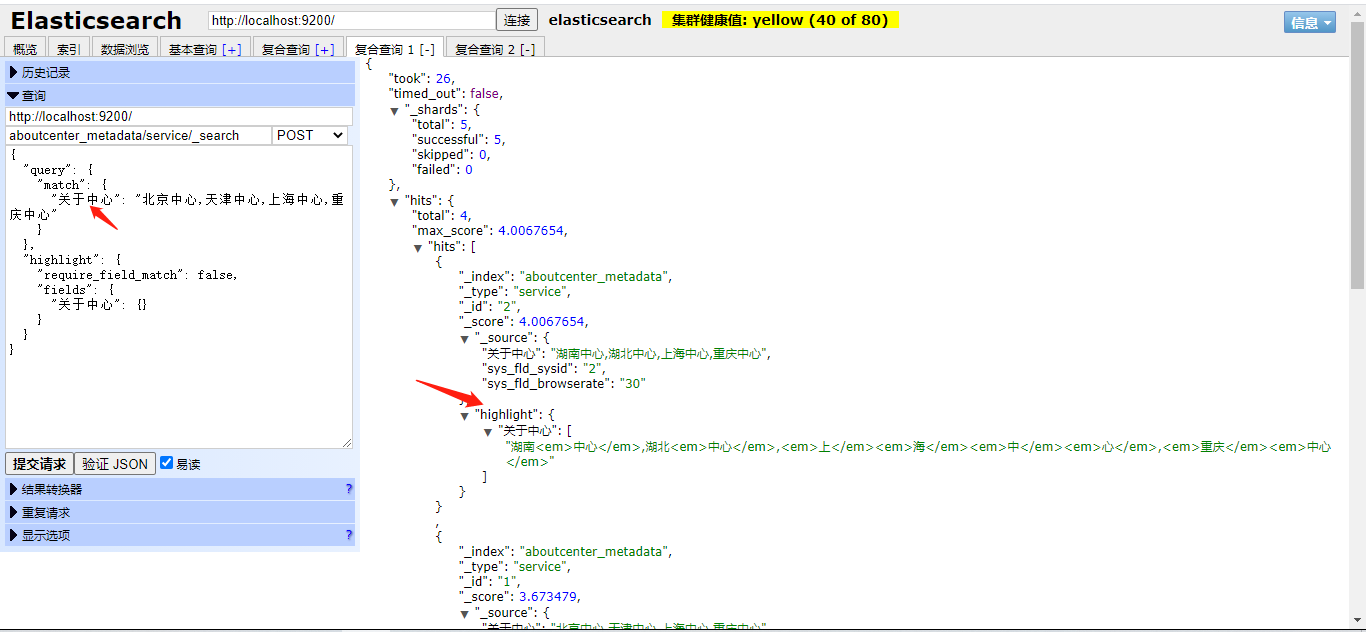
接下来问题出现了,在高亮检索时,使用.keyword进行精确检索和直接使用ik_max_word检索时,【.keyword】不返回高亮字段,请问有大佬知道为什么吗
使用【.keyword】
直接分词
相关问题
- Highlight parent path to the root
- not found value index error on elastic4s
- Issues when replicating from couchbase bucket to e
- Is there a way to sort an elasticsearch _score by
- failed to send join request to master
相关文章
- es 单字段多分词器时,textField.keyword无法高亮
- es 单字段多分词器时,textField.keyword无法高亮
- ElasticSearch: How to search for a value in any fi
- What are the disadvantages of ElasticSearch Doc Va
- NoNodeAvailableException[None of the configured no
- Types cannot be provided in put mapping requests,
- Elasticsearch cluster 'master_not_discovered_e
- Does AWS RDS encryption with KMS affect performanc
highlight里面加个关于中心.keyword